
Unlock Free, Local AI Code Completion with continue.dev + Ollama in VSCode
Ditch the paid subscriptions. Here’s how to get powerful, privacy-first AI code suggestions for $0.

Intro
If you’ve been itching to use AI-powered code completion & understanding your code but don’t want to pay for GitHub Copilot or risk sending your code to third-party servers, this post is for you.
Today, I’ll show you how to combine continue.dev’s open-source VSCode extension with a local instance of Ollama to get fast, offline-friendly code suggestions—for free.
No API keys. No subscriptions. Just your machine, a code editor, and the magic of locally running language models.
Why This Setup Rocks
Privacy: Your code never leaves your machine.
Cost: $0. Forever.
Offline Use: Code in the middle of nowhere (or on a plane).
Custom Models: Use CodeLlama, Mistral, DeepSeek Coder or any Ollama-supported model.
Step 1: Install Ollama & Load a Model
First, download and install Ollama (macOS/Linux/WSL only for now). Then, pull a coding-focused model like CodeLlama or DeepSeekCoder:
ollama pull deepseek-coder-v2:16b # capable model, slightly slowPro tip #1: Use
codellama:7bif you are finding deepseek to be slower for a slightly less capable model. Usecodellama:32bonly if you have >32GB of memory.Pro tip #2: You can list multiple models in the config and choose in the VSCode UI which model the continue.dev extension uses.
Step 2: Install the continue.dev VSCode Extension
Head to the VSCode Marketplace and install Continue.dev Coder.
Step 3: Connect continue.dev to Ollama
continue.dev defaults to cloud-based models, but we’ll reconfigure it to use your local Ollama server.
Open continue.dev’s settings (JSON) and add:
"models": [
{
"title": "DeepSeek Coder 2 16B",
"provider": "ollama",
"model": "deepseek-coder-v2",
"apiBase": "http://localhost:11434/"
}
],
"tabAutocompleteModel": {
"title": "DeepSeek Coder 2 16B",
"provider": "ollama",
"model": "deepseek-coder-v2",
"apiBase": "http://localhost:11434/"
}, (Pro tip: Continue.dev’s config.json can be found at ~/.continue/config.json on macOS.)
Restart VSCode to apply changes.
Step 4: Start Coding (with Examples!)
Let’s test it out. Ollama will run locally in the background, and continue.dev will tap into it for suggestions.
Example 1: Python Function Generation
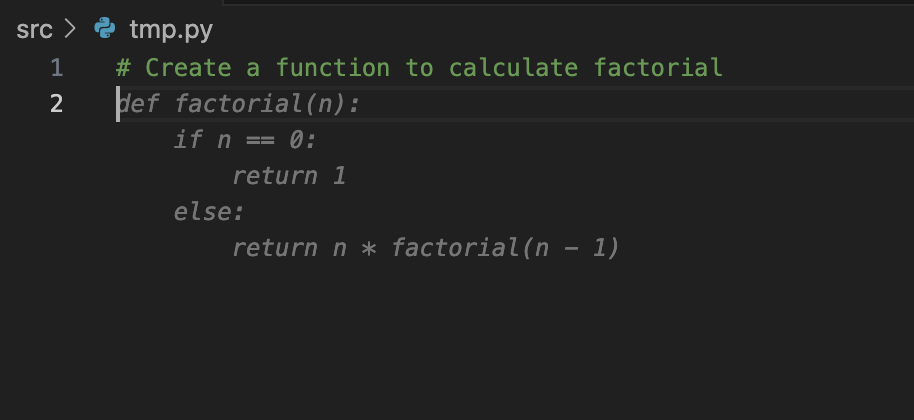
Type a comment like:
# Create a function to calculate factorial Watch continue.dev + Ollama suggest: (Use TAB to apply the suggested code)
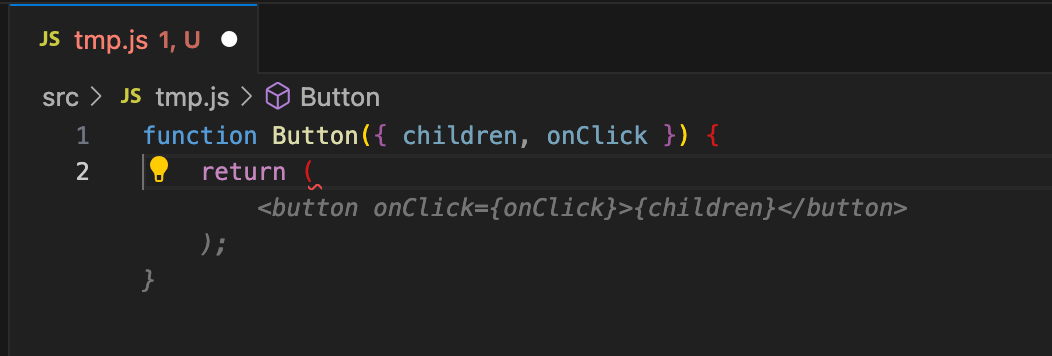
Example 2: React Component
Start typing a React component, and the model will start to auto-fill :
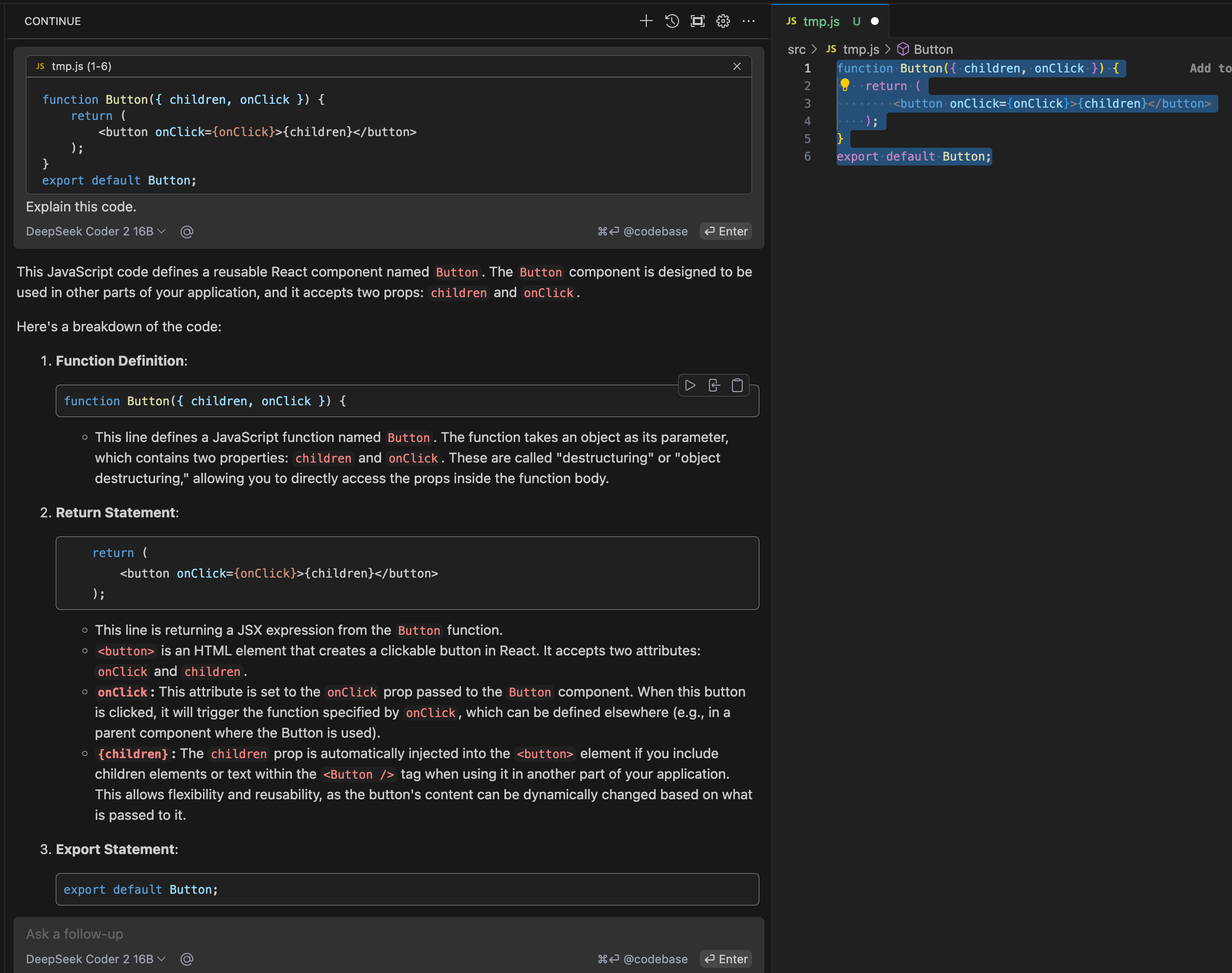
Example 3: Ask questions and get more information about your code
Highlight some code in your existing code-base, click CMD+L to start a chat window in VSCode and then you can ask the LLM questions about the code.
Troubleshooting Tips
Slow? Use smaller models (e.g.,
codellama:7binstead ofdeepseek-coder-v2:16b).No suggestions? Check if Ollama is running (
ollama serve).
Limitations
Local models (even deepseek & codellama) aren’t quite as sharp as GPT-4 or larger models like deepseek-coder-v2:236b.
Requires decent RAM (8GB+ recommended).
Final Thoughts
This setup is a game-changer for developers prioritizing privacy, cost, or offline workflows. While you won’t get ChatGPT-level nuance, CodeLlama via Ollama and continue.dev delivers surprisingly solid suggestions—and it’s completely free.
Give it a spin, and let me know how it works for you!
P.S. If you found this helpful, subscribe for more dev tools deep dives. Got questions? Drop them in the comments!